在 Elasticsearch 中,使用 PUT 请求存储一条数据(即索引一个文档)是一个涉及多个组件的复杂过程,它不仅包括数据的存储,还涵盖了数据处理、路由、复制等一系列服务。下面我们将详细解析从发起 PUT 请求到数据最终落地的完整流程。
1. 客户端发起请求
用户通过 REST API 向 Elasticsearch 集群发送一个 PUT 请求,其基本格式为:PUT /<index>/_doc/<id>。其中 <index> 是目标索引名称,<id> 是指定的文档 ID(如果省略,Elasticsearch 会自动生成一个)。请求体包含了要存储的 JSON 格式文档数据。
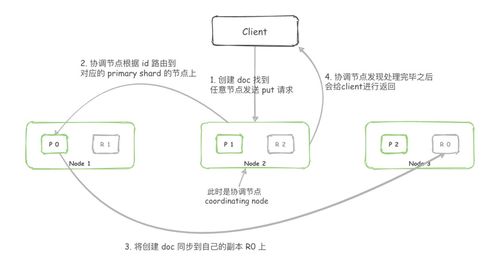
2. 请求到达协调节点
Elasticsearch 集群中的任意节点都可以接收请求,这个节点被称为“协调节点”。协调节点负责处理客户端的请求,并将其路由到正确的数据节点。它首先会解析请求,检查索引是否存在、映射是否定义等。如果索引是自动创建的(根据配置),协调节点会触发索引的创建过程。
3. 文档路由与主分片定位
Elasticsearch 索引由一个或多个主分片(及可选的副本分片)组成。协调节点根据文档 ID 计算其应该存储在哪个主分片上。默认的路由算法是:shard<em>num = hash(</em>routing) % num<em>primary</em>shards,其中 _routing 默认为文档 ID。通过计算,协调节点确定目标主分片及其所在的数据节点(称为“主分片节点”)。
4. 转发请求到主分片节点
协调节点将索引请求转发到上一步确定的主分片节点。此时,主分片节点开始本地的索引处理流程。
5. 本地索引处理(数据处理阶段)
在主分片节点上,数据会经历一系列处理步骤:
- 解析与验证:系统解析 JSON 文档,验证其结构。
- 字段映射与类型转换:根据索引的映射(mapping)定义,对字段进行类型处理。例如,将字符串日期转换为
date类型,或对文本字段进行分词设置。如果字段未预先定义且动态映射开启,Elasticsearch 会自动推断其类型并更新映射。 - 分析过程:对于文本字段(
text类型),会调用相应的分析器(analyzer)进行分词、过滤(如小写化、去除停用词等),生成倒排索引所需的词项。 - 生成文档数据结构:处理后的文档会被转换为内部存储结构,包括源文档(
_source,默认存储原始 JSON)、倒排索引条目、文档值(用于排序和聚合)等。
6. 写入事务日志与内存缓冲区
为确保数据的持久性和一致性,Elasticsearch 采用了以下步骤:
- 事务日志(Translog)写入:在数据真正写入磁盘前,操作会首先被记录到事务日志中。Translog 提供了崩溃恢复机制,防止数据丢失。
- 内存缓冲区:文档数据被添加到索引的内存缓冲区中,此时尚不可被搜索。
7. 刷新(Refresh)与可搜索性
内存缓冲区会定期刷新(默认每 1 秒一次,可通过 refresh_interval 配置)。刷新过程会:
- 将内存缓冲区中的内容写入一个新的段(segment)中,这是一个轻量级的提交。
- 重新打开索引,使得新段内的文档变得可搜索。
注意:刷新操作不会立即将数据持久化到磁盘,而是先写入文件系统缓存,速度较快。
8. 副本同步(存储支持服务的关键)
如果索引配置了副本分片(replica shards),主分片节点在本地处理完成后,会将索引请求并行转发到所有副本分片所在的节点。副本分片执行相同的本地索引处理流程。只有当所有副本分片也成功完成操作后(或根据配置的 consistency 级别),主分片节点才会向协调节点报告成功。这提供了数据的高可用性和容错能力。
9. 响应客户端
协调节点收到主分片节点的成功响应后,会向客户端返回一个确认,通常包含索引名称、文档 ID、版本号以及操作结果(如 "result": "created")。
10. 后续持久化:刷写(Flush)与段合并
为了数据的长期持久化,Elasticsearch 会定期执行刷写操作:
- Translog 刷写:当 Translog 达到一定大小时(默认 512MB)或定期(默认 30 分钟),会触发一次刷写。此时,内存中所有未持久化的段会被完全写入磁盘,同时清空 Translog。
- 段合并:由于频繁刷新会产生大量小段,Elasticsearch 会在后台自动合并小段为更大的段,优化存储和搜索性能,并删除已删除的文档。
###
Elasticsearch 的 PUT 过程是一个分布式、多阶段的数据处理与存储流程。它巧妙地将数据路由、实时处理(映射、分析)、内存缓冲、事务日志、刷新与刷写机制,以及副本复制结合起来,在保证性能、可搜索性和可靠性的提供了强大的数据存储支持服务。理解这一流程有助于更好地设计索引、调优性能和诊断问题。