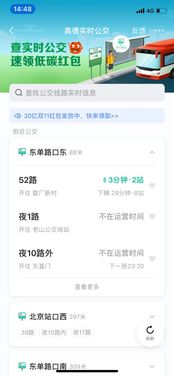
早晚高峰的通勤路上,你是否曾因踏入一辆水泄不通的公交车而后悔,或是在地铁站台面对一趟趟满员列车望车兴叹?如今,这种不确定性正逐渐成为历史。通过手机App,我们能够便捷地查询公交、地铁线路的实时拥挤度,实现“智慧择车”,从容规划行程。这项看似简单的便民功能背后,离不开一套强大、稳定且高效的数据处理与存储支持服务体系的默默支撑。
一、前端便利:实时拥挤度,出行决策新利器
用户通过App或小程序,可以直观地看到目标线路车辆的颜色标识——绿色代表宽松,黄色表示适中,红色则预警拥挤。这不仅仅是简单的“有空位”提示,而是基于实时客流分析得出的动态评估。它能帮助乘客:
1. 规避高峰车厢:选择当前相对宽松的车辆,提升出行舒适度。
2. 优化换乘方案:在有多条线路可选时,挑选拥挤度较低的路线。
3. 缓解站台压力:乘客分散候车,间接促进站台安全与秩序。
这项功能将“未知”转化为“可知”,赋予了公众更精准的出行主动权。
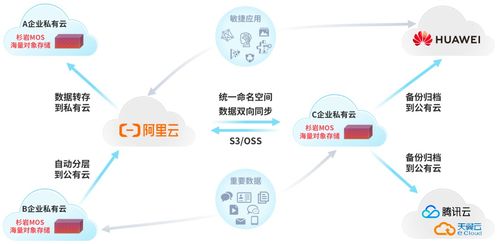
二、后端引擎:数据处理与存储服务的核心挑战与应对
实现实时拥挤度查询,技术核心在于对海量、高速、多变的数据流进行即时处理与可靠存储。主要挑战与支撑服务包括:
- 多源异构数据实时采集与接入
- 数据来源:车载摄像头、红外传感器、Wi-Fi/蓝牙嗅探、票务闸机、车辆GPS/北斗定位、乘客主动上报等。
- 支撑服务:需要强大的数据接入服务,能够兼容各种协议,以高吞吐、低延迟的方式,7x24小时不间断地从成千上万的移动终端与固定设备中接收原始数据。
- 流式数据的实时处理与分析
- 核心任务:对涌入的原始数据(如图像识别出的人数、信号连接数、定位信息)进行毫秒级计算,结合车辆容量、历史规律等模型,实时计算出每辆车的拥挤度指数。
- 支撑服务:依赖流式计算平台(如Apache Flink, Spark Streaming)。该平台能够对持续的数据流进行即时处理,实现“数据随到随算”,确保用户查询到的永远是最近几十秒内的状态,而非过时信息。
- 海量数据的高效存储与高效查询
- 存储需求:不仅要存储实时计算结果(当前拥挤度),还需归档历史数据,用于模型训练、趋势分析和运营优化。数据量随着车辆、线路和时间快速增长。
- 支撑服务:采用混合存储架构:
- 时序数据库:用于存储带有时间戳的拥挤度指标,针对时间序列数据的写入和快速查询进行了高度优化,能瞬间响应App的查询请求。
- 分布式文件系统/数据湖:用于低成本、可靠地存储原始的、结构化的历史大数据,支撑离线深度分析。
- 高速缓存:将热点线路和车辆的拥挤度数据存放在内存中,应对瞬时高并发查询(如早高峰时段),保障响应速度。
- 系统的高可用性与可扩展性
- 核心要求:公共交通服务不能中断,支撑系统必须稳定可靠。随着城市线路扩展、用户量激增,系统需能平滑扩展。
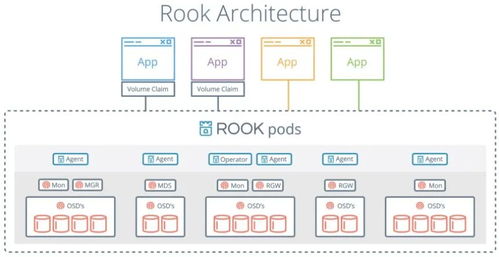
- 支撑服务:基于云计算基础设施和微服务架构。云计算提供弹性的计算、存储与网络资源,可按需伸缩;微服务架构将数据采集、处理、存储、API服务等模块解耦,单个模块的故障不影响整体,且易于独立升级扩容。
三、未来展望:从“查询”到“预测”与“调度”
当前的数据处理能力,已经为更智能的出行服务铺平了道路。系统不仅可以告知“现在挤不挤”,更能预测“等会儿挤不挤”,甚至影响“让它不再那么挤”:
- 精准预测:结合历史大数据、天气、节假日、特殊事件等因素,利用机器学习模型预测未来短时(如下一班车、半小时后)的客流拥挤情况。
- 智能调度:将实时与预测的客流数据反馈给公交地铁运营方,为动态调整发车间隔、开行区间车或大站快车提供数据决策支持,从源头优化运力配置。
- 个性化服务:与个人行程规划深度结合,为用户提供从出发地到目的地全程的“最少拥挤”或“最舒适”出行方案推荐。
“出门坐车先看它”,这一习惯的改变,是城市智慧交通迈出的坚实一步。指尖轻触所获得的便捷,其背后是一套复杂而精密的数据处理与存储服务体系在高速运转。它如同智慧交通系统的“数字心脏”,持续泵送着信息的血液,让城市交通脉络的每一次跳动都更加可知、可控、可优化。随着技术的不断演进,这颗“数字心脏”将驱动我们的城市出行向着更高效、更舒适、更人性化的方向持续前行。