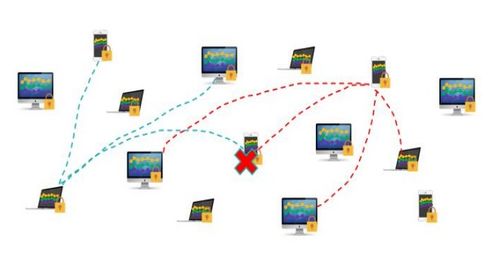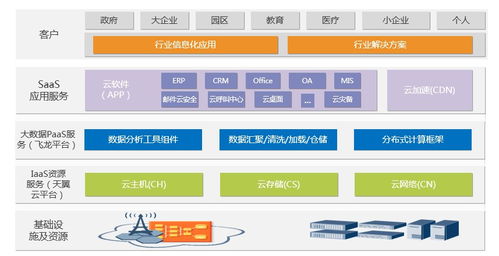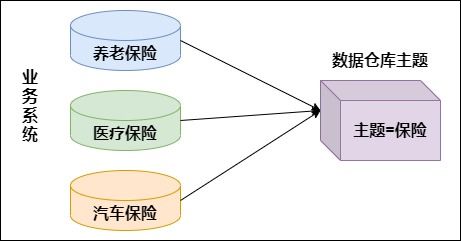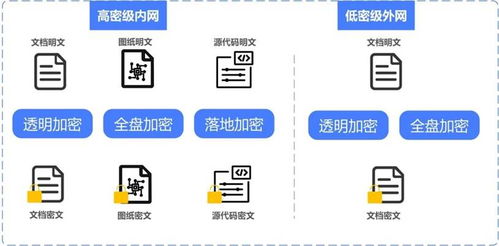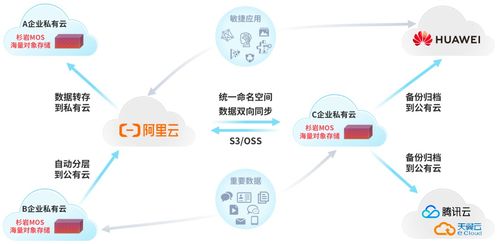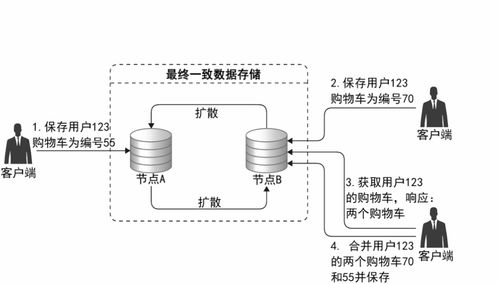
在当今大数据与高并发应用蓬勃发展的时代,传统的集中式数据存储方案已难以满足海量数据、高可用性及弹性扩展的需求。分布式数据存储作为现代架构的核心技术之一,不仅解决了数据容量与性能的瓶颈,更构建了数据处理与存储的强大支撑服务体系。本讲将深入探讨分布式数据存储的核心原理、关键技术及其如何作为服务,支撑上层应用的数据处理需求。
一、分布式数据存储的基本概念与价值
分布式数据存储是指将数据分散存储在多个独立的节点(服务器)上,这些节点通过网络互联,对外提供一个统一的逻辑视图。其核心价值在于:
- 可扩展性(Scalability):可通过水平添加节点来近乎线性地提升存储容量与处理能力。
- 高可用性与容错性(High Availability & Fault Tolerance):数据多副本存储,单个或多个节点故障不影响整体服务。
- 高性能(Performance):数据分布存储,读写负载可分散到多个节点并行处理,降低单点压力。
二、核心数据处理与存储支撑服务
分布式数据存储并非孤立的存储层,它通过一系列关键服务,为上层的应用、分析与计算提供坚实基础。
- 分布式文件系统:
- 角色:提供跨多个存储节点的统一文件命名空间,管理超大文件的块划分与分布。
- 代表技术:HDFS(Hadoop Distributed File System)、GFS(Google File System)。
- 支撑服务:为批处理框架(如MapReduce、Spark)和海量日志存储提供底层存储支持,是大数据生态的基石。
- 分布式数据库与NoSQL:
- 角色:提供结构化或半结构化数据的存储与访问,通常牺牲部分ACID特性以换取扩展性与性能。
- 分类与服务:
- 键值存储(Key-Value Store):如Redis、DynamoDB,支撑高速缓存、会话存储和简单查询场景。
- 文档数据库(Document Database):如MongoDB、Couchbase,支撑灵活 schema 的内容管理、用户档案存储。
- 列式数据库(Wide-Column Store):如Cassandra、HBase,支撑海量数据的随机实时读写,适合时序数据、监控数据。
- 图数据库(Graph Database):如Neo4j,高效支撑社交关系、推荐系统等复杂关联查询。
- 分布式协调与元数据服务:
- 角色:维护集群状态、配置信息、节点发现与领导选举,是分布式系统的“神经系统”。
- 代表技术:ZooKeeper、etcd。
- 支撑服务:为分布式数据库、微服务架构提供强一致的配置管理、分布式锁和命名服务,保障系统协调一致运行。
- 分布式缓存服务:
- 角色:将热点数据存储在内存中,极大降低后端数据库压力,提升应用响应速度。
- 代表技术:Redis(分布式模式)、Memcached。
- 支撑服务:支撑高并发读场景,如网页缓存、商品信息查询、秒杀系统。
- 数据复制与一致性服务:
- 角色:在多个节点间同步数据副本,并在一致性、可用性和分区容错性之间取得平衡(CAP定理)。
- 支撑服务:通过主从复制、多主复制、分片(Sharding)等策略,保障数据可靠性与服务连续性,是构建高可用存储服务的核心。
三、技术挑战与设计考量
在利用这些支撑服务时,架构师必须权衡以下挑战:
- 数据一致性模型:根据业务需求选择强一致性、最终一致性还是会话一致性。
- 分片策略:如何设计分片键(Shard Key)以实现数据均匀分布并避免热点。
- 故障恢复与数据再平衡:节点增删或故障时,如何自动迁移数据并恢复服务。
- 跨数据中心部署:如何实现异地多活,满足容灾与低延迟访问需求。
四、
分布式数据存储技术已演化为一套多层次、多形态的数据处理与存储支撑服务体系。从底层的文件存储,到在线的数据库与缓存,再到保障一致性的协调服务,它们共同构成了云时代和互联网规模化应用的数字基座。理解和掌握这些核心技术服务,并能够根据具体的业务场景(如数据量、读写模式、一致性要求)进行合理选型与架构设计,是每一位后端与系统架构师的必备能力。未来的趋势将朝着更智能的自动化管理、更统一的多模数据处理以及云原生深度集成等方向持续演进。