在信息爆炸的时代,大数据已成为驱动社会进步与商业创新的关键要素。其核心挑战不仅在于数据的海量性,更在于如何高效、可靠地存储这些数据,并在此基础上构建强大的数据处理与存储支持服务体系。本文将从存储架构、数据处理流程及支持服务三个维度,系统探讨大数据技术如何应对这些挑战。
一、 大数据存储:从集中到分布式的范式转变
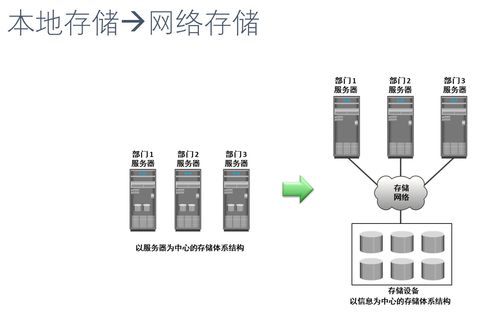
传统的关系型数据库在面对PB级甚至EB级非结构化、半结构化数据时,在扩展性、成本和处理速度上捉襟见肘。因此,大数据存储的基石转向了分布式文件系统与NoSQL数据库。
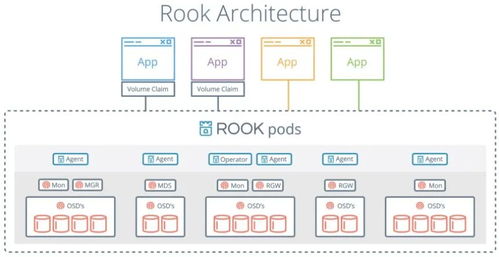
- 分布式文件系统:以Hadoop Distributed File System(HDFS)为代表,它将大文件分割成块(Block),分散存储在廉价的商用服务器集群中。这种设计不仅提供了近乎无限的横向扩展能力,还通过多副本机制确保了数据的高容错性。类似地,谷歌的GFS、阿里的盘古等也是这一理念的实践。
- NoSQL数据库:针对不同数据模型和访问模式,衍生出多种类型。键值存储(如Redis、DynamoDB)适合高速缓存与会话存储;列族存储(如HBase、Cassandra)擅长处理海量结构化与半结构化数据的随机读写;文档数据库(如MongoDB、Couchbase)以灵活的JSON/BSON格式存储复杂对象;图数据库(如Neo4j)则专注于关系网络的存储与查询。这些数据库通常采用分布式架构,牺牲了严格的事务一致性(遵循BASE原则),以换取更高的可用性与分区容错性。
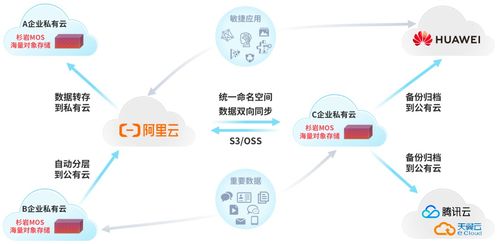
- 新兴存储范式:对象存储(如AWS S3、阿里云OSS)凭借其极佳的扩展性、耐用性和低成本,已成为海量非活跃数据(如日志、备份、多媒体)的存储标准。基于内存的分布式存储(如Apache Ignite)和时序数据库(如InfluxDB)也在特定场景下发挥着重要作用。
二、 数据处理:存储之上的计算引擎与流程
存储是基础,而数据的价值需要通过处理来释放。大数据处理形成了批处理、流处理与交互式查询并存的生态。
- 批处理:针对历史海量数据的离线计算。以Hadoop MapReduce为鼻祖,其将计算任务分发到数据所在的存储节点,遵循“移动计算而非数据”的原则,减少了网络传输开销。随后出现的Apache Spark,凭借其内存计算和DAG执行引擎,将批处理性能提升了一个数量级,成为当前的主流选择。
- 流处理:针对无界数据流的实时计算。从早期的Apache Storm,到兼具高吞吐与容错的Apache Flink,再到与Kafka深度集成的Kafka Streams,流处理技术使得实时监控、实时风控、实时推荐等应用成为可能。流处理与批处理的边界正在模糊,Lambda架构和更新的Kappa架构旨在统一处理模型。
- 交互式查询:为了实现对海量数据的快速即席查询,出现了如Apache Hive(将SQL转化为MapReduce/Spark任务)、Presto、Impala等SQL-on-Hadoop引擎,以及云数据仓库如Snowflake、BigQuery,它们提供了近乎实时的复杂查询能力。
三、 数据处理与存储支持服务:平台化与云化赋能
为使大数据技术更易用、更高效,一系列支持服务应运而生,它们将复杂的底层技术封装成可管理、可编排的服务。
- 集群管理与调度服务:如Apache YARN和Kubernetes。YARN作为Hadoop2.0的核心,将资源管理与作业调度分离,允许多种计算框架(MapReduce, Spark, Flink)共享集群资源。Kubernetes则以其强大的容器编排能力,成为部署和管理云原生大数据组件的首选,实现了更灵活的资源隔离与弹性伸缩。
- 数据编排与生命周期管理:Apache Airflow、DolphinScheduler等工作流调度工具,用于编排复杂的数据处理管道(ETL)。数据湖管理框架如Delta Lake、Apache Iceberg和Hudi,在分布式存储之上提供了ACID事务、版本控制、模式演进等能力,使得数据湖更加可靠和易于管理。数据目录服务(如Apache Atlas)则实现了数据的元数据管理和血缘追踪,保障数据治理。
- 云存储与计算服务:公有云厂商(如AWS, Azure, 阿里云)提供了全托管的大数据服务。例如,对象存储(S3/OSS)作为几乎无限容量的底层存储;EMR、Databricks等托管集群服务简化了Spark/Hadoop的运维;云原生数据仓库(Redshift、BigQuery、AnalyticDB)则开箱即用,用户无需关心底层基础设施。这种“存储与计算分离”的架构,结合按需付费的模式,极大地降低了企业使用大数据技术的门槛和总拥有成本(TCO)。
与展望
大数据存储已从单一的数据库解决方案,演进为一个多层次、多模态的分布式生态系统。数据处理引擎正朝着流批一体、湖仓融合的方向发展,以提供更统一和高效的数据处理体验。而围绕数据处理与存储的支持服务,特别是云服务的普及,正使得大数据能力从技术专家的手中, democratize(民主化)到更广泛的业务与数据分析人员。随着人工智能与机器学习工作负载的深度集成,以及对数据隐私、安全与合规性要求的不断提高,大数据存储与处理体系将持续演进,其核心将始终围绕如何更经济、更智能、更安全地存储数据,并从中提取最大价值。